
Data growth and managing the costs involved with it are becoming an increasingly important aspect of any deployed business system. When addressing this issue with SAP HANA there are a range of considerations which need to be taken into account:
- License cost (SAP HANA is licensed on used memory capacity and feature usage)
- Hardware cost (Primarily the cost of additional memory and if DRAM capacity exceeds a certain amount, then additional CPU sockets and/or servers with additional CPU sockets may be needed)
- Cost of additional storage
- Rate of data growth over a period of time
- How often different tables are used in comparison to one another?
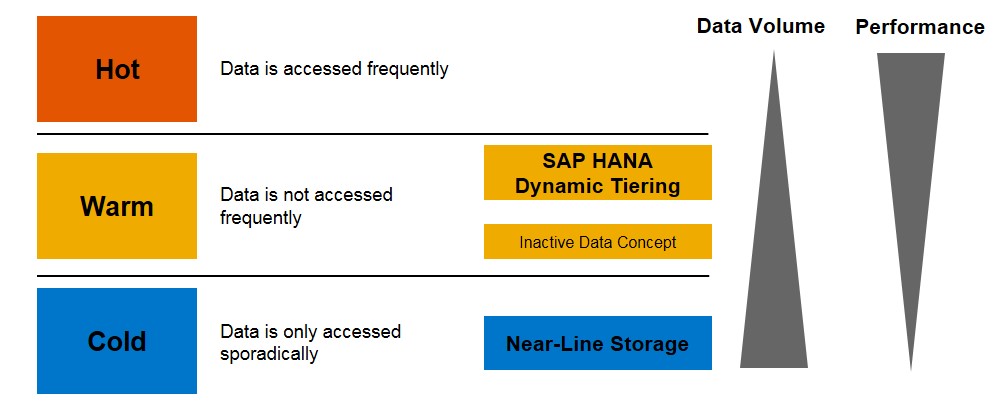
To solve these questions SAP created a concept known as “data temperature management” which in simple terms is a way in which to specify where and how different types of data can be accessed. This concept implies that different data can be separated into three distinct groups based on what it is used for and how often that data is accessed:
| Temperature | Definition | Location/accessed from |
| Hot Data | Data accessed and modified frequently. Typically used in day to day business operations. | In-Memory data. Usually DRAM or PMEM. |
| Warm Data | Data accessed infrequently, usually for read only business operations performed at the end of a quarter or during routine auditing operations. | Disk storage or a separate system, usually accessed by loading pages of data into memory and then using these to generate query results. |
| Cold Data | Data rarely accessed, usually retained for legal and/or retention policy purposes. | External storage, managed separately from the SAP HANA database. |
It is implicit that hot data will be a small amount of data requiring high performance while cold data is the highest quantity requiring the lowest performance.
Here I want to talk about managing warm data using extension nodes in an SAP HANA Scale out deployment. I have setup a scale out (distributed system) landscape based on HANA 2.0 SPS04 using 4, 2 socket servers with 512GB of memory each. The sizing requirements when using extension nodes to only contain warm data is relaxed as long as the underlying size of the storage data volume allows the required quantity. An extension node can be “overloaded” which means that it is possible to have multiple times the normal amount of data on that node, as long as the required amount of memory in the server for query processing has been taken into account. The minimum scale out system must contain one HANA worker node for hot data and one hana extension node for warm data.
With an extension node, objects (tables, partitions, etc) are physically redistributed to different locations based on a DDL specification, therefore allowing the separation of hot and warm data by moving “warm specified” data to only the extension node.
| Name | Role | Data/Log Volume size |
| SHN1 | Worker (Master) |
768GB/ 256GB |
| SHN2 | Worker | |
| SHN3 | Worker | |
| SHN4 | Worker (Extension Node) | 3072GB/ 256GB |
If a standby node is required then it is very easy to change the landscape to allow for this.
| Name | Role | Data/Log Volume size |
| SHN1 | Worker (Master) | 768GB/ 256GB |
| SHN2 | Worker | |
| SHN3 | Worker (Extension Node) | 3072GB/ 256GB |
| SHN4 | Standby | N/A |
Configuring Extension Nodes
Step 1. Assign the extension node to the “worker_dt” worker group
This can be done during installation by specifying the worker group for the node, or via an SQL command executed as a user with the correct permissions:
| call SYS.UPDATE_LANDSCAPE_CONFIGURATION (‘SET WORKERGROUPS’, ‘shn4’, ‘worker_dt’) |
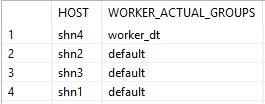
To identify the correct node is added to the worker group run the SQL command:
| SELECT HOST, WORKER_ACTUAL_GROUPS FROM SYS.M_LANDSCAPE_HOST_CONFIGURATION |
Step 2. Exclude the extension nodes volumes from the volume list for table redistribution
Determine the volume list of all nodes which will store and process hot data
| SELECT v.host, v.port, v.volume_id FROM M_VOLUMES v JOIN M_LANDSCAPE_HOST_CONFIGURATION c ON v.host = c.host WHERE v.service_name = ‘indexserver’ AND c.worker_actual_groups != ‘worker_dt’ |
The command will give us the output, pay particular attention to the volume id field.
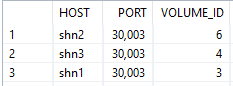
In this instance the volume ID’s are 6, 4 and 3. These need to be taken and another SQL command is executed to overwrite the default settings for table placement.
| ALTER SYSTEM ALTER CONFIGURATION (‘global.ini’,’SYSTEM’) SET (‘table_placement’, ‘LOCATION_ALL’) = ‘6, 4 ,3’ WITH RECONFIGURE; |
At this point, unless otherwise specified, hot data will only be located on the volumes attached to SHN1, SHN2 and SHN3.
Specifying and/or redistributing data to the extension node
At this point the extension node is setup, but when using native HANA applications additional planning and implementation is required to use this data temperature management technique, effectively.
In the below examples I will use the “User1” schema, the location for “all” will be used for hot data and the group type name for warm data will be named “warm_data”.
Before doing anything to the database objects I need to define the table placement rules for tables with hot data, this can be done by executing the following command:
| ALTER SYSTEM ALTER TABLE PLACEMENT (SCHEMA_NAME => ‘USER1’) SET (LOCATION => ‘all’, MIN_ROWS_FOR_PARTITIONING => 0, INITIAL_PARTITIONS => 1, REPARTITIONING_THRESHOLD => 0); |
Then I define the table placement for tables with warm data using the worker group “worker_dt”
| ALTER SYSTEM ALTER TABLE PLACEMENT (SCHEMA_NAME => ‘USER1’, GROUP_TYPE => ‘warm_data’) SET (LOCATION => ‘worker_dt’, MIN_ROWS_FOR_PARTITIONING => 0, INITIAL_PARTITIONS => 1, REPARTITIONING_THRESHOLD => 0); |
At this point any table created with the DDL attribute “GROUP TYPE “warm_data”” will be directed towards the extension node, otherwise the table will be located on any of the hot worker nodes. This process needs to be done for each schema containing warm data for an extension node.
An example of DDL when creating tables in the warm data tier:
| CREATE TABLE WarmDataTable(hot int, cold int) GROUP TYPE “warm_data”; |
An example of altering existing tables to move to the warm data tier:
| ALTER TABLE WarmDataTable SET GROUP TYPE “warm_data” |
An example of altering an existing table to move it out of the warm data tier:
| ALTER TABLE WarmDataTable UNSET GROUP; |
If a tables group type is altered then a redistribution needs to be run before it can be relocated to the extension node, this can be accomplished by running the following SQL command:
| CALL REORG_GENERATE (6,’GROUP_TYPE=>warm_data’);
CALL REORG_EXECUTE(?); |
In the event that an extension node needs to be reverted back to a normal worker node, the worker group just needs to be set back to default by running the following SQL command:
| CALL SYS.UPDATE_LANDSCAPE_CONFIGURATION (‘SET WORKERGROUPS’, ‘shn4’, ‘default’); |
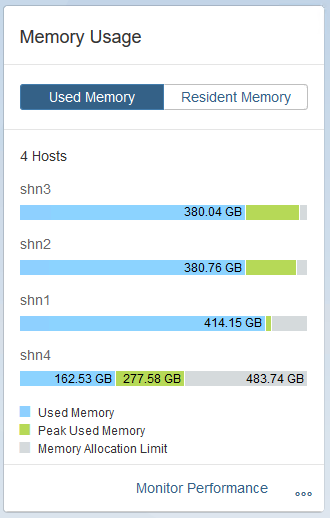
Now to see an extension node in action, I have 1TB of hot data which I want to move 80% of it into the warm tier. Used memory as seen below is around 1.1 TB across the 3 hot data nodes.
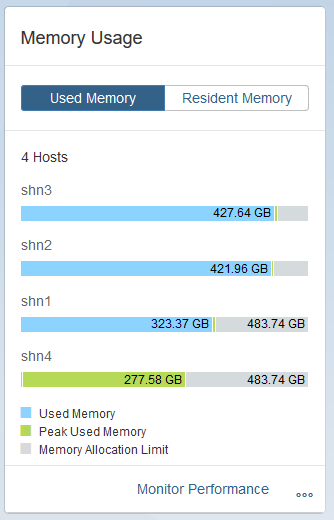
I then specify the relevant tables which need to move to the extension node and start the redistribution. After a bit of time I can see the used memory dropping on the normal worker nodes , and rising on the extension node.
Note: To see which tables are specified to use the group type, use the SQL command:
| select * from SYS.TABLE_GROUPS |
Once the table redistribution was complete, I noted a significant drop in memory use on the normal worker nodes. I did note that while redistributing that memory usage on the extension node hit a limit, and I needed to unload some of the tables to ensure that an out of memory event did not occur.
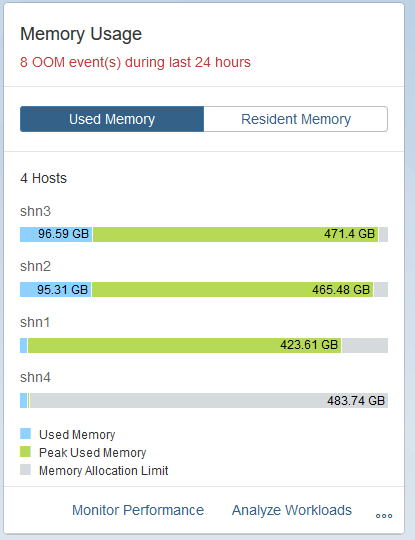
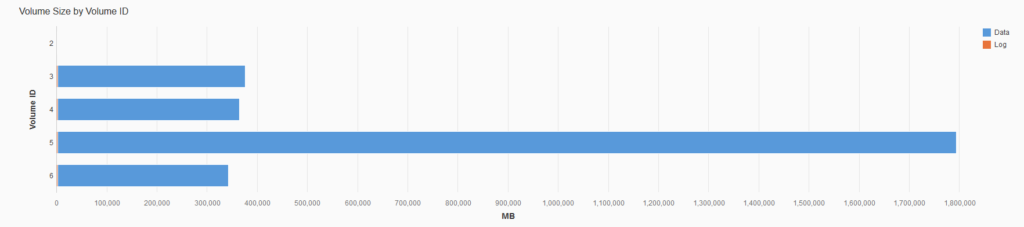
And then finally when looking at the used storage for all nodes in the scale out deployment, the extension node is holding a significant amount more data than the normal worker nodes.
Resources
SAP Note 2415279 – How To: Configuring SAP HANA for the SAP HANA Extension Node